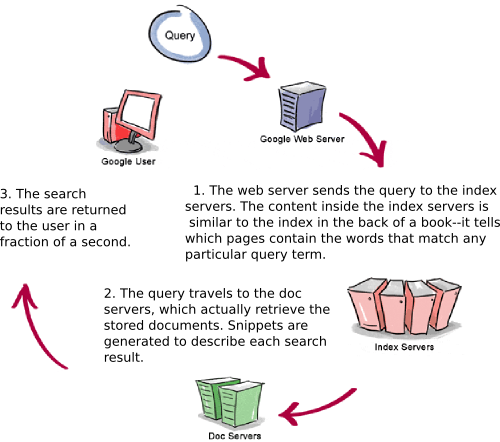
Google funziona su una rete distribuita di migliaia di computer a basso costo e può quindi effettuare una rapida elaborazione in parallelo. L’elaborazione parallela è un metodo di calcolo in cui molti calcoli possono essere eseguiti contemporaneamente ed accelera significativamente l’elaborazione dei dati. Google si divide in tre parti distinte:
- Googlebot, un web crawler che trova e recupera pagine web;
- L’indicizzatore che ordina ogni parola in ogni pagina e memorizza l’indice risultante delle parole in un database enorme;
- Il processore di query, che mette a confronto l’indice della query di ricerca e raccomanda i documenti che ritiene più rilevanti.
1. Googlebot, Google Web Crawler
Googlebot è il robot di Google, che trova e recupera le pagine sul web e li consegna all’indicizzatore di Google. Funziona proprio come il browser web, inviando una richiesta a un server per una pagina web, scaricare l’intera pagina. Googlebot è costituito da molti computer e preleva le pagine molto più rapidamente con il nostro browser web. In realtà, Googlebot può richiedere migliaia di pagine contemporaneamente. Per evitare l’intasamento dei server, Googlebot rende volutamente più lente le richieste di ogni singolo server. Googlebot rileva pagine in due modi: attraverso un modulo add URL, www.google.com / addurl.html e attraverso la ricerca di link dalla scansione del web.
Purtroppo, gli spammer hanno capito come creare bot automatici che hanno bombardato il modulo add URL con milioni di URL che puntano alla propaganda commerciale. Google respinge quegli URL inviati che cercano di ingannare gli utenti, utilizzando tattiche come anche il testo nascosto o link in una pagina, piena di parole con le irrilevanti, utilizzando reindirizzamento, la creazione di portali, domini o sottodomini con contenuti sostanzialmente simili, l’invio a Google query automatizzate. Così ora il modulo Add URL dispone anche di un test: visualizza alcune lettere ondulate progettate per ingannare i robot automatizzati, attraverso il codice captcha che ci chiede di inserire le lettere che vediamo sullo schermo. Questa tecnica punta a limitare l’azione degli spam bot.
Quando Googlebot recupera una pagina, i link presenti sulla pagina sono aggiunti in coda per la scansione successiva. Raccogliendo i collegamenti di ogni pagina, Googlebot può rapidamente costruire una lista di link in grado di coprire ampie propaggini del Web. Questa tecnica, nota come scansione profonda, permette a Googlebot di sondare nel profondo i singoli siti. La scansione in profondità può raggiungere quasi ogni pagina del web: poiché il web è vasto, l’operazzione può richiedere un certo tempo, per cui alcune pagine possono essere sottoposte a scansione solo una volta al mese. I duplicati in coda devono essere eliminati per evitare che Googlebot li recuperi nuovamente la stessa pagina. Googlebot deve determinare la frequenza di rivisitazione di una pagina.
2. Google Indexer
Googlebot dà all’indicizzatore il testo completo delle pagine che trova. Queste pagine sono memorizzate nel database di Google. Questo indice è ordinato alfabeticamente per termine di ricerca, ad ogni voce di indice è memorizzato un elenco di documenti in cui compare il termine e la posizione all’interno del testo in cui si verifica. Questa struttura dati permette l’accesso rapido ai documenti che contengono termini della query utente. Per migliorare le prestazioni di ricerca, Google ignora (non index) parole comuni chiamati stop words (come l’ , è , a , o , di , come , perché , oltre ad alcune cifre e lettere singole). Le parole di stop sono così comuni che fanno poco per limitare una ricerca, e quindi possono essere tranquillamente eliminati. L’indicizzatore ignora anche alcuni spazi e punteggiatura multipla, così come la conversione tutte le lettere in minuscolo, per migliorare le prestazioni di Google.
3. Processore di query di Google
Il processore di query ha varie parti, inclusa l’interfaccia utente (casella di ricerca), il “motore“che valuta le domande e corrisponde a documenti rilevanti e il formattatore risultati. Il PageRank è il sistema di Google per le pagine web ranking. Una pagina con un PageRank più alto è considerata più importante ed è più probabile essere elencati sopra una pagina con un PageRank più basso. Google prende in considerazione oltre un centinaio di fattori di calcolo di un PageRank per determinare quali siano i documenti più rilevanti per una query, tra cui la popolarità della pagina, la posizione, le dimensioni dei termini di ricerca all’interno della pagina e la vicinanza dei termini di ricerca tra loro sulla pagina.
Google vale anche tecniche di machine-learning per migliorare le prestazioni automaticamente imparando relazioni e associazioni all’interno dei dati memorizzati. Ad esempio, il sistema ortografico-correzione utilizza tali tecniche per capire ortografie alternative possibili. Google sorveglia da vicino le formule utilizzati per calcolare la pertinenza; sono messo a punto per migliorare la qualità e le prestazioni, e per sconfiggere le ultime tecniche subdole utilizzate dagli spammer.
Indicizzare il testo completo consente a Google di andare oltre la semplice corrispondenza termini di ricerca singoli. Google dà maggiore priorità alle pagine che contengono i termini di ricerca e nello stesso ordine della query. Google può anche abbinare più parole nelle frasi e frasi intere. Dal momento che Google indicizza il codice HTML in aggiunta al testo della pagina, gli utenti possono limitare le ricerche sulla base del luogo in cui appaiono le parole della query, ad esempio, nel titolo, nell’URL, nel corpo e nel link alla pagina, le opzioni offerte dal modulo di ricerca avanzata di Google e Operatori di Ricerca (Operatori avanzati) .
Vediamo come Google elabora una query.